凸优化笔记17:次梯度下降
对于光滑函数,我们可以用梯度下降法,并且证明了取不同的步长,可以得到次线性收敛,如果加上强凸性质,还可以得到线性收敛速度。那如果现在对于不可导的函数,我们就只能沿着次梯度下降,同样会面临步长的选择、方向的选择、收敛性分析等问题。
1. 收敛性分析
次梯度下降的一般形式为 \[ x^{(k)}=x^{(k-1)}-t_{k} g^{(k-1)}, \quad k=1,2, \ldots \quad g\in\partial f(x^{(k-1)}) \] 一般有 3 种步长的选择方式:
- fix step: \(t_k\) 为常数
- fix length:\(t_{k}\left\|g^{(k-1)}\right\|_{2}=\left\|x^{(k)}-x^{(k-1)}\right\|_{2}\) 为常数
- diminishing:\(t_{k} \rightarrow 0, \sum_{k=1}^{\infty} t_{k}=\infty\)
要证明这几种方法的收敛性,需要先引入 Lipschitz continuous 假设,即 \[ |f(x)-f(y)| \leq G\|x-y\|_{2} \quad \forall x, y \] 这等价于 \(\Vert g\Vert_2\le G\) 对任意 \(g\in\partial f(x)\) 都成立。
在分析收敛性之前,我们需要引入一个非常重要的式子:arrow_down:!!!在后面的分析中会一直用到: \[ \begin{aligned} \left\|x^{+}-x^{\star}\right\|_{2}^{2} &=\left\|x-t g-x^{\star}\right\|_{2}^{2} \\ &=\left\|x-x^{\star}\right\|_{2}^{2}-2 t g^{T}\left(x-x^{\star}\right)+t^{2}\|g\|_{2}^{2} \\ & \leq\left\|x-x^{\star}\right\|_{2}^{2}-2 t\left(f(x)-f^{\star}\right)+t^{2}\|g\|_{2}^{2} \end{aligned} \] 那么如果定义 \(f_{\mathrm{best}}^{(k)}=\min _{0 \leq i<k} f\left(x^{(i)}\right)\),就有 \[ \begin{aligned} 2\left(\sum_{i=1}^{k} t_{i}\right)\left(f_{\text {best }}^{(k)}-f^{\star}\right) & \leq\left\|x^{(0)}-x^{\star}\right\|_{2}^{2}-\left\|x^{(k)}-x^{\star}\right\|_{2}^{2}+\sum_{i=1}^{k} t_{i}^{2}\left\|g^{(i-1)}\right\|_{2}^{2} \\ & \leq\left\|x^{(0)}-x^{\star}\right\|_{2}^{2}+\sum_{i=1}^{k} t_{i}^{2}\left\|g^{(i-1)}\right\|_{2}^{2} \end{aligned} \] 根据上面的式子,就可以得到对于
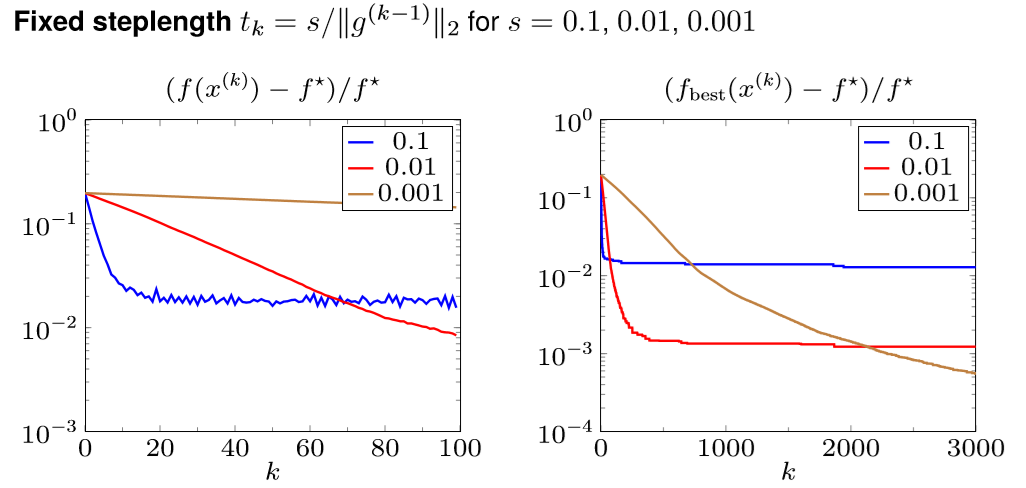
Fixed step size:\(t_i=t\) \[ f_{\text {best }}^{(k)}-f^{\star} \leq \frac{\left\|x^{(0)}-x^{\star}\right\|_{2}^{2}}{2 k t}+\frac{G^{2} t}{2} \] Fixed step length:\(t_{i}=s /\left\|g^{(i-1)}\right\|_{2}\) \[ f_{\text {best }}^{(k)}-f^{\star} \leq \frac{G\left\|x^{(0)}-x^{\star}\right\|_{2}^{2}}{2 k s}+\frac{G s}{2} \] 这两个式子中的第一项都随着 \(k\) 增大而趋于 0,但第二项却没有办法消掉,也就是与最优解的误差不会趋于 0。并且他们有一个微妙的不同点在于,fixed step size 情况下 \(G^2t/2\sim O(G^2),Gs/2\sim O(G)\),\(G\) 一般是较大的。
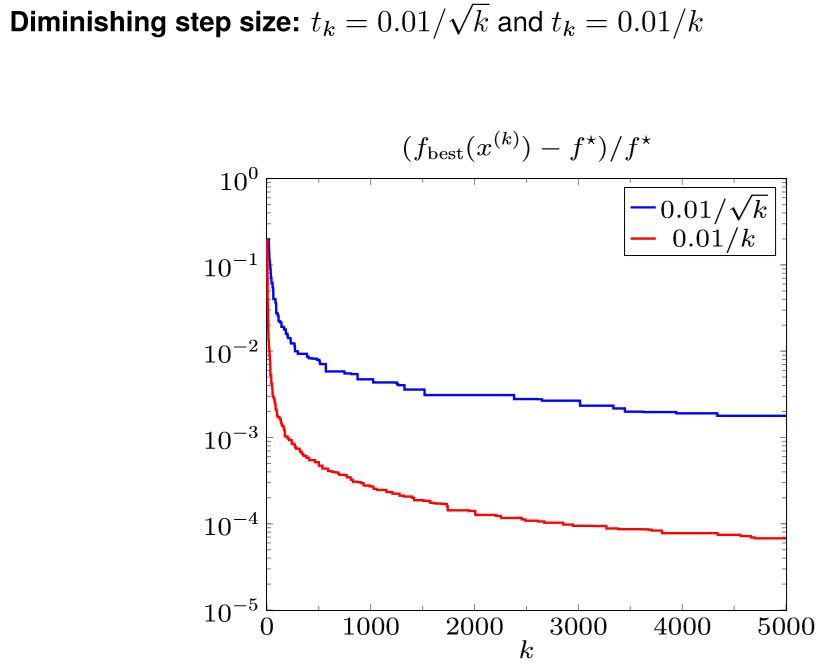
Diminishing step size:\(t_{k} \rightarrow 0, \sum_{k=1}^{\infty} t_{k}=\infty\) \[ f_{\text {best }}^{(k)}-f^{\star} \leq \frac{\left\|x^{(0)}-x^{\star}\right\|_{2}^{2}+G^{2} \sum_{i=1}^{k} t_{i}^{2}}{2 \sum_{i=1}^{k} t_{i}} \] 可以证明,\(\left(\sum_{i=1}^{k} t_{i}^{2}\right) /\left(\sum_{i=1}^{k} t_{i}\right) \rightarrow 0\),因此 \(f_{\text {best }}^{(k)}\) 会收敛于 \(f^\star\)。
下面看几幅图片,对于优化问题 \(\min\Vert Ax-b\Vert_1\)
| Fixed step length | Diminishing step size |
|---|---|
 |
 |
前面考虑了固定步长的情况,假设现在我们固定总的迭代次数为 \(k\),可不可以优化步长 \(s\) 的大小来尽可能使 \(f_\text{best}^{(k)}\) 接近 \(f^\star\) 呢?这实际上可以表示为优化问题 \[ f_{\text {best }}^{(k)}-f^{\star} \leq \frac{R^{2}+\sum_{i=1}^{k} s_{i}^{2}}{2 \sum_{i=1}^{k} s_{i}/G} \Longrightarrow \min_s \frac{R^{2}}{2 ks/G}+\frac{s}{2/G} \] 其中 \(R=\left\|x^{(0)}-x^{\star}\right\|_{2}\),那么最优步长为 \(s=R/\sqrt{k}\),此时 \[ f_{\text {best }}^{(k)}-f^{\star} \leq \frac{GR}{\sqrt{k}} \] 因此收敛速度为 \(O(1/\sqrt{k})\),对比之前光滑函数的梯度下降,收敛速度为 \(O(1/k)\)。
我们对前面的收敛速度并不满意,如果有更多的信息,比如已知最优解 \(f^\star\) 的大小,能不能改进收敛速度呢?根据前面的式子,有 \[ \left\|x^{+}-x^{\star}\right\|_{2}^{2} \leq\left\|x-x^{\star}\right\|_{2}^{2}-2 t_i\left(f(x)-f^{\star}\right)+t_i^{2}\|g\|_{2}^{2} \] 这实际上是关于 \(t_i\) 的一个二次函数,因此可以取 \(t_{i}=\frac{f\left(x^{(i-1)}\right)-f^{\star}}{\left\|g^{(i-1)}\right\|_{2}^{2}}\),就可以得到 \[ f_{\text {best }}^{(k)}-f^{\star} \leq \frac{GR}{\sqrt{k}} \] 可见还是没有改进收敛速度。
如果引入强凸性质呢?如果假设满足 \(\mu\) 强凸,则 \(f^\star \ge f^k+g^{kT}(x^k-x^\star)+\mu/2\Vert x^k-x^\star\Vert_2^2\),可以取 \(t_k=\frac{2}{\mu(k+1)}\),那么就可以得到 \[ f_{\text {best }}^{(k)}-f^{\star} \leq \frac{2G^2}{\mu(k+1)} \]