凸优化笔记16:次梯度 Subgradient
前面讲了梯度下降的方法,关键在于步长的选择:固定步长、线搜索、BB方法等,但是如果优化函数本身存在不可导的点,就没有办法计算梯度了,这个时候就需要引入次梯度(Subgradient),这一节主要关注次梯度的计算。
1. 次梯度
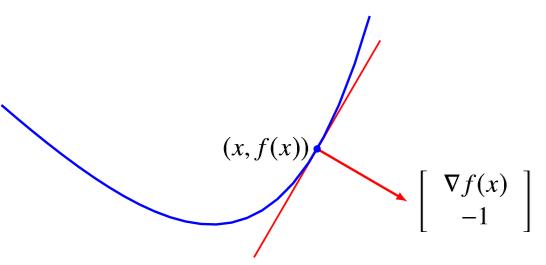
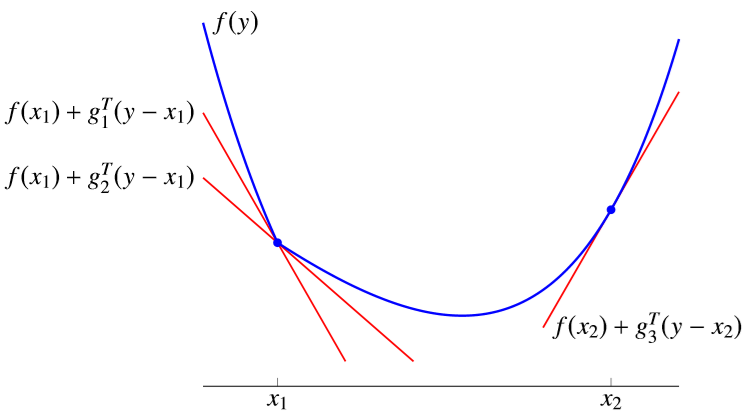
次梯度(subgradient)的定义为 \[ \partial f(x)= \{g|f(y)\ge f(x)+g^T(y-x),\forall y\in\text{dom} f \} \] 该如何理解次梯度 \(g\) 呢?实际上经过变换,我们可以得到 \[ \left[\begin{array}{c} g \\ -1 \end{array}\right]^{\top}\left(\left[\begin{array}{l} y \\ t \end{array}\right]-\left[\begin{array}{c} x \\ f(x) \end{array}\right]\right) \leq 0, \forall(y, t) \in \operatorname{epi}f \] 实际上这里 \([g^T \ -1]^{T}\) 定义了 epigraph 的一个支撑超平面,并且这个支撑超平面是非垂直的,如下面的图所示
| 光滑函数 | 非光滑函数 |
|---|---|
 |
 |
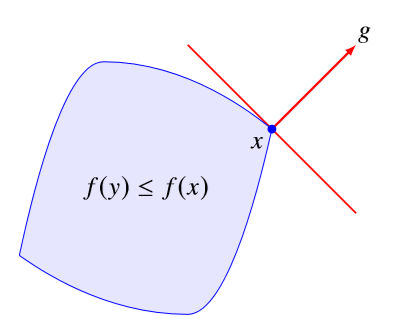
而对于任意的下水平集 \(\{y|f(y)\le f(x)\}\),都有 \[ f(y)\le f(x) \Longrightarrow g^T(y-x)\le0 \] 这说明次梯度 \(g\) 实际上也是下水平集的一个支撑超平面
Remarks:很有意思的一件事是函数的梯度 \(\nabla f\) 包含有大量的信息,他的方向代表了函数下降最快的方向,也就是下水平集的法线方向;而他的模长代表了下降的速度,\([\nabla f\ -1]^T\) 是 epigraph 的法线方向,可以直观想象,如果 \(\Vert \nabla f\Vert\) 越大,那么这个法线方向越趋向于水平,也就是说 epigraph 的标面越趋近于竖直,函数下降速度当然也越快。
每个点的次梯度 \(\partial f(x)\) 实际上是一个集合,我们先来看这个集合有什么性质呢?我们先列出来然后一一解释:
- 次梯度映射是单调算子
- 如果 \(x\in\text{ri dom}f\),则 \(\partial f(x)\ne \varnothing\),而且是有界、闭的凸集
- \(x^\star= \arg\min f(x) \iff 0\in \partial f(x^\star)\)
首先,他是一个 set-valued mapping,而且是一个单调算子,也即 \[ (u-v)^T(y-x)\ge0,\forall u\in\partial f(y),v\in\partial f(x) \] 这个性质很容易由定义导出。
其次,内点处的次梯度总是非空的闭凸集,且有界。
首先可以证明其非空,(默认我们考虑的 \(f\) 为凸函数)因为函数 \(f\) 是凸的,其 epigraph 在 \((x,f(x))\) 一定存在一个支撑超平面 \[ \exists(a, b) \neq 0, \quad\left[\begin{array}{l} a \\ b \end{array}\right]^{T}\left(\left[\begin{array}{l} y \\ t \end{array}\right]-\left[\begin{array}{c} x \\ f(x) \end{array}\right]\right) \leq 0 \quad \forall(y, t) \in \text { epi } f \] 由于 \(t\) 可以趋于 \(+\infty\),因此 \(b\le0\),如果 \(b=0\),由于 \(x\) 为内点,也很容易导出矛盾,因此可以证明 \(b<0\),于是就可以得到 \(g=a/|b|\)。
其次可以证明其为闭凸集,次梯度还可以表示为 \[ \begin{aligned} \partial f(x)&= \{g|f(y)\ge f(x)+g^T(y-x),\forall y\in\text{dom} f \} \\ &= \bigcap_{y\in \text{dom}f} \{g|g^T(y-x)\le f(y)-f(x) \} \end{aligned} \] 这是很多个半空间的交集,因此 \(\partial f(x)\) 是一个闭的凸集。
最后可以证明次梯度集合是有界的,为了证明他有界,只需证明他的 \(l_\infty\) 范数有界即可。可以取 \[ B=\left\{x \pm r e_{k} | k=1, \ldots, n\right\} \subset \operatorname{dom} f \] 定义 \(M=\max _{y \in B} f(y)<\infty\),应用次梯度的定义就可以得到 \[ \|g\|_{\infty} \leq \frac{M-f(x)}{r} \quad \text { for all } g \in \partial f(x) \] 注意上面的非空、有界、闭凸集都要求 \(x\) 为定义域的内点,如果是边界上则无法保证。
例子 1:对于凸集 \(C\),定义函数 \(\delta_C(x)=\begin{cases}0,&x\in C\\+\infty,&x\notin C\end{cases}\),那么次梯度为 \[ \begin{aligned} g\in\partial \delta_C(x) &\iff \delta_C(y)\ge \delta_C(x)+g^T(y-x),\forall y\in C \\ &\iff g^T(y-x)\le0, \forall y\in C \\ &\iff g\in N_C(x) \quad \text{ (normal cone at $x$)} \end{aligned} \] Remarks:集合 \(C\) 的 normal cone 的定义为 \[ \forall x\in C,\quad N_C(x)=\{g| g^T(y-x)\le0,\forall y\in C\} \] 例子 2:函数 \(f(x)=\vert x\vert,\partial f(x)=\begin{cases}1,&x>0\\ [-1,1],&x=0\\ -1&x<0\end{cases}\)
例子 3:函数 \(f(x)=\Vert x\Vert_2,\partial f(0)=\{g|\Vert g\Vert_2\le1\}\)
例子 4:对于任意范数 \(f(x)=\Vert x\Vert\) \[ \partial f(x)=\{y|\Vert y\Vert_*\le1,\left<y,x\right>=\Vert x\Vert \} \] 证明:\(\forall g\in\partial f(x)\),需要 \(\Vert y\Vert \ge \Vert x\Vert+ g^T(y-x)\quad(\Delta)\)
可以取 \(y=2x \Longrightarrow \Vert x\Vert \ge g^Tx\),也可以取 \(y=0\Longrightarrow 0\ge \Vert x\Vert-g^Tx\),因此有 \(g^Tx=\Vert x\Vert\)
由 \((\Delta)\) 式可知应有 \(\Vert y\Vert \ge g^Ty \iff \Vert g\Vert_*\le1\)。
2. 次梯度计算
每个点的次梯度是一个集合,这里有两个概念
Weak subgradient calculus:只需要计算其中一个次梯度就够了;
Strong subgradient calculus:要计算出 \(\partial f(x)\) 中的所有元素。
要想计算出所有的次梯度是很难的,所以大多数时候只需要得到一个次梯度就够了,也就是 Weak subgradient calculus。不过,对于下面这几种特殊情况,我们可以得到完整的次梯度描述(也即 Strong subgradient calculus),他们是:
- 如果 \(f\) 在 \(x\) 是可微的,那么 \(\partial f(x)=\{\nabla f(x)\}\)
- 非负线性组合:\(f(x)=\alpha_1 f_1(x)+\alpha_2 f_2(x)\),那么 \(\partial f(x)=\alpha_1 \partial f_1(x)+\alpha_2 \partial f_2(x)\),第二个式子是集合的加法;
- 仿射变换:\(f(x)=h(Ax+b)\),那么 \(\partial f(x)=A^T h(Ax+b)\)
对于第一条的证明,我们可以取 \(y=x+r(p-\nabla f(x)),p\in\partial f(x)\),那么根据次梯度的定义就有 \(\Vert p-\nabla f(x)\Vert^2\le \frac{O(r^2)}{r}\to0\) 随着 \(r\to0\),因此就有 \(\nabla f(x)=p\)。
对于第三条的证明,只需要分别证明 \(A^T h(Ax+b) \subseteq \partial f(x)\) 和 \(\partial f(x) \subseteq A^T h(Ax+b)\),前者很容易,主要是后者。由于次梯度 \(d\in \partial f(x)\) 需要满足 \(f(z)\ge f(x)+d^T(z-x) \iff h(Az+b)-d^Tz\ge h(Ax+b)-d^Tx\),也就是说 \((x,Ax+b)\) 实际上是如下问题的最优解 \[ \begin{aligned} \min \quad& h(z)-d^Ty \\ \text{s.t.}\quad& Ay+b = z,\quad z\in\text{dom}h \end{aligned} \] 如果 \((Range(A)+b)\cap \text{ri dom}h \ne \varnothing\),说明 SCQ 成立,则强对偶性成立,于是根据拉格朗日对偶原理有 \[ \exists \lambda,\text{ s.t. }(x,Ax+b) \in \arg\min \{h(z)-d^Ty+\lambda^T(Ay+b-z)\} \\ \Longrightarrow \begin{cases} \nabla_y L(y,z,\lambda)=0 \Longrightarrow 0\in \partial h(z)-\lambda \\ \nabla_z L(y,z,\lambda)=0 \Longrightarrow d=A^T\lambda \end{cases} \] 推论:根据第 3 条,可以得到:如果考虑函数 \(F(x)=f_1(x)+...+f_m(x)\),且 $_i f_i$,则 \(\partial F(x)=\partial f_1(x)+... + \partial f_m(x)\)。(这个实际上可以直接右上面的第二条得到,这里只不过又验证了一次)
证明:我们可以考虑函数 \(f(x)=f_1(x_1)+...+f_m(x_m)\),在定义 \(A=[I,...,I]^T\),那么就有 \(F(x)=f(Ax)\),所以 \(\partial F(x)=A^T \partial f(Ax)=[I\ ...\ I][\partial f_1(x),...,\partial f_m(x)]^T = \partial f_1(x)+... + \partial f_m(x)\)。
上面是能获得 Strong subgradient calculus 的几个原则,对于其他情况,我们考虑找到一个次梯度就够了。下面给出一些常见的情况。
点点最大值:\(f(x)=\max\{f_1(x),...,f_m(x) \}\),可以定义 \(I(x)=\{i|f_i(x)=f(x)\}\),那么他的
- weak result:choose any \(g\in\partial f_k(x)\),其中 \(k\in I(x)\)
- strong result:\(\partial f(x)=\text{conv}\bigcup_{i\in I(x)}\partial f_i(x)\)
点点上确界:\(f(x)=\sup_{\alpha\in \mathcal{A}} f_\alpha (x)\),其中 \(f_\alpha(x)\) 关于 \(x\) 是凸的,定义 \(I(x)=\{\alpha\in\mathcal{A}|f_\alpha(x)=f(x)\}\),那么
- weak result:choose any \(g\in\partial f_\beta (\hat{x})\),其中 \(f(\hat{x})=f_\beta(\hat{x})\)
- strong result:\(\text{conv}\bigcup_{\alpha\in I(x)}\partial f_\alpha(x) \subseteq \partial f(x)\),如果要取等号,需要额外的条件
下确界:\(f(x)=\inf_y h(x,y)\),其中 \(h(x,y)\) 关于 \((x,y)\) 是联合凸的,那么
- weak result:\((g,0)\in \partial h(\hat{x},\hat{y})\),其中 \(\hat{y}=\arg\min h(\hat{x},y)\)
复合函数:\(f(x)=h(f_1(x),...,f_k(x))\),其中 \(h\) 为单调不减的凸函数,\(f_i\) 为凸函数
- weak result:\(g=z_1g_1+...+z_kg_k,z\in\partial h(f_1(x),...,f_k(x)),g_i\in \partial f_i(x)\)
期望:\(f(x)=\mathbb{E}h(x,u)\),其中 \(u\) 为随机变量,\(h\) 对任意的 \(u\) 关于 \(x\) 都是凸的
- weak result:选择函数 \(u\mapsto g(u),g(u)\in \partial_x h(\hat{x},u)\),则 \(g=\mathbb{E}_u g(u) \in \partial f(\hat{x})\)
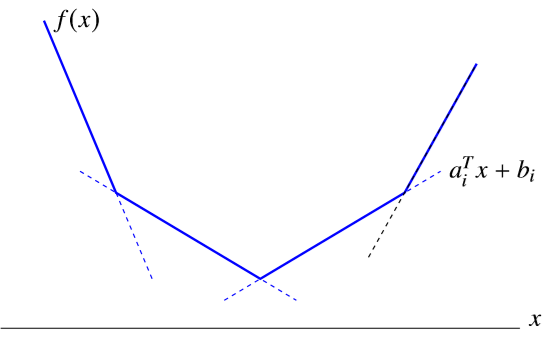
例子 1:picewise-linear function \(f(x)=\max_{i=1,...,m}(a_i^Tx+b_i),\partial f(x)=\text{conv}\{a_i|i\in I(x)\}\)
例子 2:\(l_1\) 范数 \(f(x)=\Vert x\Vert_1=|x_1|+...+|x_n|,\partial f(x)=J_1\times \cdots \times J_n\),其中 \(J_k=\begin{cases}[-1,1]&x_k=0\\ {1}&x_k>0\\ {-1}&x_k<0 \end{cases}\)
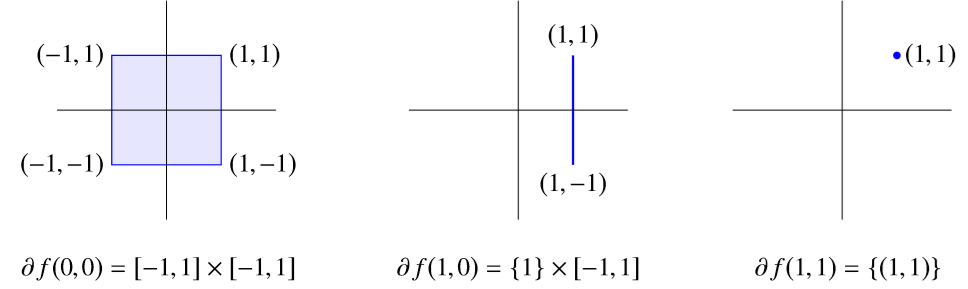
例子 3:\(f(x)=\lambda_{\max}(A(x))=\sup_{\Vert y\Vert_2=1}y^TA(x)y\),其中 \(A(x)=A_0+x_1A_1+\cdots +x_nA_n\),则取 \(\lambda_{\max}(A(\hat{x}))\) 对应的单位特征向量 \(y\),次梯度可以表示为 \((y^TA_1y,...,y^TA_ny)\in \partial f(\hat{x})\)
例子 4:到凸集的欧氏距离 \(f(x)=\inf_{y\in C}\Vert x-y\Vert_2=\inf_{y} h(x,y)\),其中集合 \(C\) 为凸集,函数 \(h\) 关于 \((x,y)\) 是联合凸的。 \[ g=\begin{cases}0&\hat{x}\in C\\ \frac{1}{\|\hat{y}-\hat{x}\|_{2}}(\hat{x}-\hat{y})=\frac{1}{\|\hat{x}-P(\hat{x})\|_{2}}(\hat{x}-P(\hat{x})) & \hat{x}\notin C \end{cases} \] 例子 5:定义如下凸优化问题的最优解为 \(f(u,v)\) \[ \begin{aligned} \text{minimize} \quad& f_{0}(x) \\ \text{subject to}\quad& f_{i}(x) \leq u_{i}, \quad i=1, \ldots, m\\ &A x=b+v \end{aligned} \] 如果假设 \(f(\hat{u},\hat{v})\) 有界且强对偶性成立,那么对于对偶问题如下对偶问题 \[ \begin{aligned} \text{maximize} \quad& \inf _{x}\left(f_{0}(x)+\sum_{i} \lambda_{i}\left(f_{i}(x)-\hat{u}_{i}\right)+v^{T}(A x-b-\hat{v})\right) \\ \text{subject to}\quad& \lambda\succeq 0 \end{aligned} \] 若其最优解为 \((\hat\lambda,\hat\nu)\),则有 \((-\hat\lambda,-\hat\nu)\in \partial f(\hat{u},\hat{v})\)。
3. 对偶原理与最优解条件
前面我们对于可导函数获得了对偶原理以及 KKT
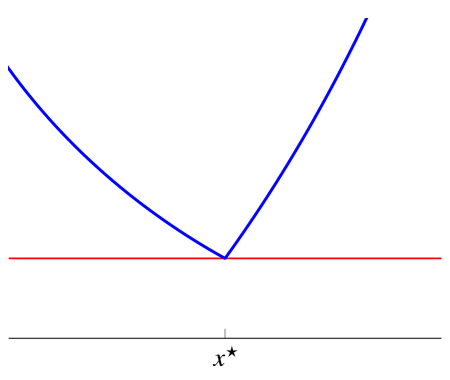
条件,那如果是不可导的函数呢?我们有 \[
f(y) \geq f\left(x^{\star}\right)+0^{T}\left(y-x^{\star}\right) \quad
\text { for all } y \quad \Longleftrightarrow \quad 0 \in \partial
f\left(x^{\star}\right)
\] 
例子:对于优化问题 \(\min f(x),\text{s.t. }x\in C \iff \min f(x)+\delta_C(x)=F(x)\),因此 \[ 0\in \partial f(x^\star)+\partial \delta_C(x^\star) \Longrightarrow \exists p\in\partial f(x^\star),\quad\text{s.t.}-p\in \partial\delta_C(x^\star)=N_C(x^\star) \] 如果 \(f\in C^1\),则有 \(-\nabla f(x^\star)\in N_C(x^\star)\)。
KKT 条件怎么变呢?只需要修改一下梯度条件:
- 原问题可行性 \(x^\star\) is primal feasible
- 对偶问题可行性 \(\lambda^\star \succeq0\)
- 互补性条件 \(\lambda_i^\star f_i(x^\star)=0,i=1,...,m\)
- 梯度条件 \(0\in \partial f_0(x^\star)+\sum_i \lambda_i^\star \partial f_i(x^\star)\)
4. 方向导数
方向导数(directional derivative)的定义为 \[ \begin{aligned} f^{\prime}(x ; y) &=\lim _{\alpha \searrow 0} \frac{f(x+\alpha y)-f(x)}{\alpha} \\ &=\lim _{t \rightarrow \infty}\left(tf\left(x+\frac{1}{t} y\right)-t f(x)\right) \end{aligned} \] 方向导数是齐次的,也即 \[ f'(x;\lambda y)=\lambda f'(x;y) \quad \text{for }\lambda\ge0 \] 对于凸函数,方向导数也可以定义为 \[ \begin{aligned} f^{\prime}(x ; y) &=\inf _{\alpha > 0} \frac{f(x+\alpha y)-f(x)}{\alpha} \\ &=\inf _{t >0}\left(tf\left(x+\frac{1}{t} y\right)-t f(x)\right) \end{aligned} \] 要证明的话,只需要证明 \(g(\alpha)=\frac{f(x+\alpha y)-f(x)}{\alpha}\) 随着 \(\alpha\) 单调递减有下界。
实际上方向导数定义了沿着 \(y\) 方向的函数下界,也即 \[ f(x+\alpha y) \geq f(x)+\alpha f^{\prime}(x ; y) \quad \text { for all } \alpha \geq 0 \] 对于凸函数,\(x\in\text{int dom}f\),也有 \[ f^{\prime}(x ; y)=\sup _{g \in \partial f(x)} g^{T} y \] 也即 \(f'(x;y)\) 是 \(\partial f(x)\) 的支撑函数
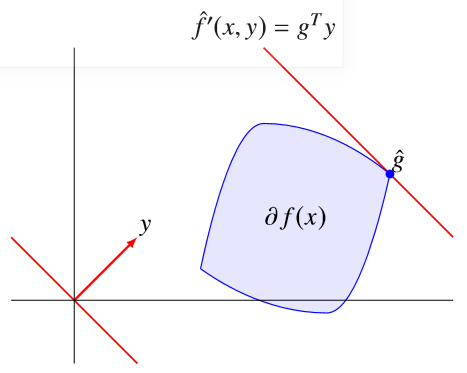
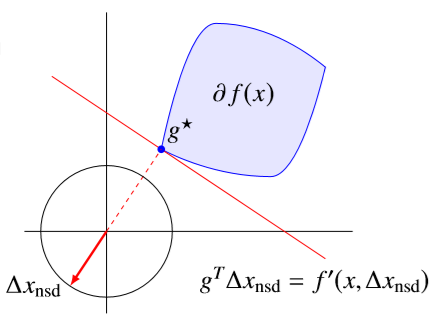
Remarks:需要注意的是负的次梯度方向不一定是函数值下降方向,而只有方向导数 <0 的方向才是函数值下降方向。反例如下图
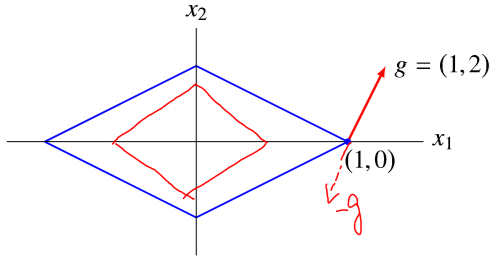
如果我们想找到下降最快的方向(Steepest descent direction),则需要 \[ \Delta x_{\mathrm{nsd}}=\underset{\|y\|_{2} \leq 1}{\operatorname{argmin}} f^{\prime}(x ; y) \] 根据前面的式子我们知道 \(\min f'(x;y)=\min_{\Vert y\Vert_2\le1}\sup_{g\in\partial f(x)}g^Ty\),如果假设极大极小可以换序,则可以等价为 \(\sup_g \inf_y g^Ty = \sup_{g\in\partial f(x)} -\Vert g\Vert_2\),上面过程可以表述为原问题与对偶问题 \[ \begin{aligned} \text{minimize} \quad& f'(x;y) \\ \text{subject to}\quad& \|y\|_{2} \leq 1 \end{aligned} \qquad \begin{aligned} \text{minimize} \quad& -\|g\|_{2} \\ \text{subject to}\quad& g \in \partial f(x) \end{aligned} \] 于是就有 \(f^{\prime}\left(x ; \Delta x_{\mathrm{nsd}}\right)=-\left\|g^{\star}\right\|_{2}\),\(\text { if } 0 \notin \partial f(x), \Delta x_{\mathrm{nsd}}=-g^{\star} /\left\|g^{\star}\right\|_{2}\),如下图所示