凸优化笔记26:不动点迭代
前面讲了很多具体的算法,比如梯度、次梯度、近似点梯度、加速近似点梯度、PPA、DR方法、ADMM、ALM等,对这些方法的迭代过程有了一些了解。这一节则主要是针对算法的收敛性进行分析,试图从一个更加抽象的层面,利用不动点迭代的思想,把上面的算法综合起来,给一个比较 general 的收敛性分析方法。
1. 什么是不动点?
对于希尔伯特空间(Hilbert space) \(\mathcal{H}\),定义了内积 \(\left<\cdot,\cdot\right>\) 和 范数 \(\|\cdot\|\)(可以借助于 \(\mathbb{R}^2\) 来想象)。算子 \(T:\mathcal{H}\to\mathcal{H}\)(或者是 \(C\to C\),\(C\) 为 \(\mathcal{H}\) 的闭子集)。那么算子 \(T\) 的不动点集合就定为 \[ \mathrm{Fix} T:=\{x \in \mathcal{H}: x=T(x)\} \] 如果不动点集合非空,想要研究的是不动点迭代 \(x^{k+1}\leftarrow T(x^k)\) 的收敛性。为了简便,常把 \(T(x)\) 写为 \(Tx\)。
为什么要研究不动点迭代呢?因为前面我们讲的算法里面很多都可以表示为这种形式。
例子 1(GD):对于无约束优化 \(\min f(x)\),不假设 \(f\) 一定是凸的。如果有 \(\nabla f(x^\star)=0\),那么 \(x^\star\) 被称为驻点(stationary point)。梯度下降做的什么事呢?\(x^{k+1}=x^k-\gamma \nabla f(x^k)\),所以实际上算子 \(T\) 为 \[ T:=I-\gamma \nabla f \] 我们要找的最优解 \(x^\star\) 满足 \(\nabla f(x^\star)=0\Longrightarrow x^\star=T(x^\star)\),因此我们要找的就是 \(T\) 的不动点。
例子 2(PG1):对于有约束优化 \(\min f(x),\text{ s.t. }x\in C\),假设 \(f\) 为正常的闭凸函数,\(C\) 为非空闭凸集。对于这个带约束的优化问题,我们可以做完一步梯度下降以后再做个投影 \(x^{k+1}\leftarrow \operatorname{proj}_{C}(x^k-\gamma \nabla f(x^k))\),所以有 \[ T:=\operatorname{proj}_{C}(I-\gamma \nabla f) \] 而我们要找的最优解需要满足 \(\left\langle\nabla f\left(x^{\star}\right), x-x^{\star}\right\rangle \geq 0 \quad \forall x \in C \iff 0\in \nabla f(x^\star)+\partial \delta_C(x^\star)\),这实际上还是在找 \(T\) 的不动点。
例子 3(PG2):上面向 \(C\) 的投影实际上也是在算 \(\text{prox}\) 算子。对于优化问题 \(\min f(x)+g(x)\) 我们要解的方程是 \[ \begin{array}{c}0\in \nabla f(x)+\partial g(x) \iff 0\in x+\nabla f(x)-x+\partial g(x) \\\iff (I-\nabla f)(x)\in (I+\partial g)(x) \\\iff x=(I+\partial g)^{-1}(I-\nabla f)(x)\end{array} \] 上一节讲到了 \((I+\partial g)^{-1}\) 就是 \(\text{prox}\) 算子,所以这个不动点迭代就等价于近似点梯度方法。
例子 4(KKT):对于优化问题 \[ \begin{aligned}\min\quad& f_0(x) \\\text{s.t.}\quad& g(x)\le0 \\& h(x)=0\end{aligned} \] 拉格朗日函数为 \(L(x,\lambda,\nu)=f_0(x)+\lambda^T g(x)+\nu^T h(x),\lambda\ge0\),KKT 条件就是要求解方程 \[ T(x,\lambda,\nu)=\left[\begin{array}{c}\partial_x L(x,\lambda,\nu) \\-f(x)+\partial \delta_{\{\lambda\ge0\}}(x) \\h(x)\end{array}\right]=0 \] 也就是要找到 \(\tilde{T}=I+T\) 的不动点。
上面几个例子主要为了说明很多优化算法都可以写成不动点迭代的形式,那么要想分析他们的收敛性,只需要分析不动点迭代的收敛性就可以了,下面要讲的就是这件事情。
2. 收敛性分析
要想分析收敛速度,必须要引入的一个性质就是 Lipschitz 连续。
定义:算子 \(T\) 是 \(L\)-Lipschitz 的,\(L\in[0,+\infty)\),如果它满足 \[ \|T x-T y\| \leq L\|x-y\|, \quad \forall x, y \in \mathcal{H} \] 定义:算子 \(T\) 是 \(L\)-quasi-Lipschitz 的,\(L\in[0,+\infty)\),如果对任意 \(x^\star\in \text{Fix}T\) 它满足 \[ \|T x-x^\star\| \leq L\|x-x^\star\|, \quad \forall x \in \mathcal{H} \]
2.1 收缩算子收敛性
定义:算子 \(T\) 是收缩算子(contractive),如果它满足 \(L\)-Lipschitz,\(L\in[0,1)\)
定义:算子 \(T\) 是准收缩算子(quasi-contractive),如果它满足 \(L\)-quasi-Lipschitz,\(L\in[0,1)\)
准收缩算子很形象,它说明每次迭代之后,我们都会距离不动点 \(x^\star\) 更近一点。
下面是一个证明收敛性的重要定理!
定理(Banach fixed-point theorem):如果 \(T\) 是收缩算子,那么
- \(T\) 有唯一的不动点 \(x^\star\)(存在且唯一)
- \(x^k\to x^\star\)(强收敛)
- \(\| x^k-x^\star\|\le L^k\|x^0-x^\star\|\)(线性收敛速度)
证明:略。
例子 1(GD):对于一般的 \(\min f(x)\),我们假设 \(f\) 为 Lipschitz-differentiable 并且是 strongly-convex 的(回忆GD的收敛速度证明)那么就有(假设 \(f\in C^2\)) \[ mI\le \nabla^2 f\le LI \] 梯度下降的算子为 \(T=I-\gamma \nabla f\),我们需要计算这个算子的 Lipschitz 常数 \[ \begin{array}{c}(1-\alpha L)I\le D(I-\alpha\nabla f)=I-\alpha \nabla^2 f(x)\le(I-\alpha m)I \\\| D(I-\alpha\nabla f)\| \le \max(|1-\alpha m|,|1-\alpha L|)\end{array} \] 注:\(T=I-\gamma \nabla f\) 里面的 \(I\) 表示算子,\(I-\alpha \nabla^2 f(x)\) 里边的 \(I\) 就表示对角元素等于 1 的矩阵,虽然形式一样,但意义不太一样。
如果要想 \(T\) 是收缩算子,则需要 \(\alpha\in(0,2/L)\),这也是为什么我们前面章节证明 GD 收敛性的时候需要步长 \(t\le 2/L\)。
例子 2:如果是对于一般的算子,我们想要求解 \(0\in F(x)\),类比梯度下降方法,可以有 \(x^{k+1}=x^k-\alpha Fx^k\),\(T=I-\alpha F\)。类似的,我们也假设 \(F\) 为 \(m\) strongly monotone,\(L\)-Lipschitz 的,那么有 \[ \begin{aligned}\| Tx-Ty\|^2_2 &=\| (I-\alpha F)(x)-(I-\alpha F)(y)\|^2_2 \\&= \|x-y\|_2^2 - 2\alpha(Fx-Fy)^T(x-y)+\alpha^2\|Fx-Fy\|^2_2 \\&\le (1-2\alpha m+\alpha^2L^2)\|x-y\|^2\end{aligned} \] 所以当 \(\alpha\in\left(0,\frac{2m}{L^2}\right)\) 的时候 \(T\) 是收缩算子,可以证明收敛性。
跟前面梯度下降对比,前面只要求 \(\alpha <2/L\),所以梯度下降的要求更宽松。即使不满足强凸性质,梯度下降也能保证收敛,但是这里就必须要有 \(m\) strongly monotone,这是因为梯度算子提供了更多的信息。
2.2 非扩张算子收敛性
前面的收缩算子要求 \(L<1\),这个条件还是比较强的,很多时候只能得到 \(L=1\),这个时候被称为 nonexpansive,也就是非扩张的。这个时候
- \(T\) 可能不存在不动点 \(x^\star\)
- 如果 \(x^\star\) 存在,不动点迭代 \(x^{k+1}=Tx^k\) 有界
- 可能会发散(这个发散我个人不太理解,或许不收敛也被认为是发散)
比如说旋转、反射操作,如图所示
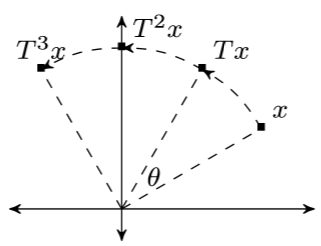
那么对于这种算子怎么证明收敛性呢?如果得不到收缩性质,那么我们可以放松一点要求,比如得到下面的 \[ \|T x-T y\|^{2} \leq\|x-y\|^{2}-\eta\|R x-R y\|^{2}, \quad \forall x, y \in \mathcal{H} \] 这个算子 \(R\) 一会再说,虽然我们还是只能有 \(L=1\),但是每次迭代之后都可以减少一点小尾巴,累积起来就能收敛到不动点了。那么就让我们再引入一些定义吧。
定义不动点残差算子 \(R:=I-T\),有 \(Rx^\star=0\iff x^\star=Tx^\star\)。
定义:若 \(T\) 对于某些 \(\eta>0\) 满足下式,则称其为平均算子(averaged operator) \[ \|T x-T y\|^{2} \leq\|x-y\|^{2}-\eta\|R x-R y\|^{2}, \quad \forall x, y \in \mathcal{H} \] 定义:若 \(T\) 对于某些 \(\eta>0\) 满足下式,则称其为准平均算子(quasi-averaged operator) \[ \left\|T x-x^{*}\right\|^{2} \leq\left\|x-x^{*}\right\|^{2}-\eta\|R x\|^{2}, \quad \forall x \in \mathcal{H} \] 我们也可以表示为 \(\eta:=\frac{1-\alpha}{\alpha}\),从而将上面平均算子称为 \(\alpha\)-averaged operator。如果 \(\alpha=1/2\),称 \(T\) 为 firmly nonexpansive;如果 \(\alpha=1\),称 \(T\) 为 nonexpansive。
引理:\(T\) 是 \(\alpha\)-averaged operator,当且仅当存在一个 nonexpansive \(T'\) 使得 \[ T=(1-\alpha)I+\alpha T' \] 或者等价的有算子 \[ T^{\prime}:=\left(\left(1-\frac{1}{\alpha}\right) I+\frac{1}{\alpha} T\right) \] 是 nonexpansive。
证明:通过代数运算可以得到 \[ \alpha\left(\|x-y\|^{2}-\left\|T^{\prime} x-T^{\prime} y\right\|^{2}\right)=\|x-y\|^{2}-\|T x-T y\|^{2}-\frac{1-\alpha}{\alpha}\|R x-R y\|^{2} \] 因此 \(T'\) nonexpansive \(\iff\) T \(\alpha\)-averaged。证毕。
有了 \(\alpha\)-averaged 性质,我们也可以得到一个收敛性的定理。
定理(Krasnosel’skii):\(T\) 为 \(\alpha\)-averaged 算子,且不动点存在,则迭代方法 \[ x^{k+1}\leftarrow Tx^k \] 弱收敛至 \(T\) 的不动点。
证明:略。
定理(Mann’s version):\(T\) 为 nonexpansive 算子,且不动点存在,则迭代方法 \[ x^{k+1} \leftarrow\left(1-\lambda_{k}\right) x^{k}+\lambda_{k} T x^{k} \] 弱收敛至 \(T\) 的不动点,只要满足 \[ \lambda_{k}>0, \quad \sum_{k} \lambda_{k}\left(1-\lambda_{k}\right)=\infty \] 证明:略。
Mann’s version 相当于是对 Krasnosel’skii 的一个推广,每一步都取一个不同的 \(\alpha\)。
例子 1(PPA):对于 \(\min f(x)\),近似点算子 \[ T:=\operatorname{prox}_{\lambda f} \] 就是 firmly-nonexpansive,因此可以弱收敛。
2.3 复合算子
对于多个算子复合,有以下性质:
- \(T_{1}, \ldots, T_{m}: \mathcal{H} \rightarrow \mathcal{H}\) contractive \(\Longrightarrow T_{1} \circ \cdots \circ T_{m}\) contractive
- \(T_{1}, \ldots, T_{m}: \mathcal{H} \rightarrow \mathcal{H}\) nonexpansive \(\Longrightarrow T_{1} \circ \cdots \circ T_{m}\) nonexpansive
- \(T_{1}, \ldots, T_{m}: \mathcal{H} \rightarrow \mathcal{H}\) averaged \(\Longrightarrow T_{1} \circ \cdots \circ T_{m}\) averaged
- \(T_i\) 是 \(\alpha_i\)-averaged(允许 \(\alpha_i=1\)) \(\Longrightarrow T_{1} \circ \cdots \circ T_{m}\) 是 \(\alpha\)-averaged,其中
\[ \alpha=\frac{m}{m-1+\frac{1}{\max _{i} \alpha_{i}}} \]
例子:如第一小节的投影梯度、PG。
3. 更一般的情况
我们的优化问题可以概括为求解方程 \[ 0\in(A+B)(x) \] 其中 \(A,B\) 为算子,那么对这个式子做变形就能得到很多方法。
Forward-backward: \[ \begin{aligned}0\in(A+B)(x) &\iff 0\in(I+\alpha B)(x)-(I-\alpha A)(x) \\&\iff (I-\alpha A)(x)\in(I+\alpha B)(x) \\&\iff x=(I+\alpha B)^{-1}(I-\alpha A)(x)\end{aligned} \] Forward-backward-forward: \[ \begin{aligned}0\in(A+B)(x) &\iff x=(I+\alpha B)^{-1}(I-\alpha A)(x) \\&\iff (I-\alpha A)(x)= (I-\alpha A)(I+\alpha B)^{-1}(I-\alpha A)(x) \\&\iff x=\left((I-\alpha A)(I+\alpha B)^{-1}(I-\alpha A)+\alpha A\right)(x)\end{aligned} \] Combetts-Pesquest: \[ \begin{aligned}0\in(A+B+C)(x) &\iff \begin{cases}0\in Ax+u+Cx \\ u\in Bx \end{cases} \\&\iff 0\in \left[\begin{array}{c}Ax \\ B^{-1}u\end{array}\right] + \left[\begin{array}{c}u+Cx \\ -x\end{array}\right]\end{aligned} \] DR splitting: \[ \begin{aligned}0\in(A+B)(x) \iff (\frac{1}{2}I+\frac{1}{2}C_A R_B)(z)=z,\quad x=R_B(z)\\\end{aligned} \] 其中
\(C_A\):Cayley operator,\(C_A=2R_A-I=2\text{prox}_f-I\)
\(R_B\):resolvent operator,\(R_B=(z)=(I+B)^{-1}(z)\)