凸优化笔记21:加速近似点梯度下降
我们证明了梯度方法最快的收敛速度只能是 \(O(1/k^2)\)(没有强凸假设的话),但是前面的方法最多只能达到 \(O(1/k)\) 的收敛速度,那么有没有方法能达到这一极限呢?有!这一节要讲的加速近似梯度方法(APG)就是。这个方法的构造非常的巧妙,证明过程中会发现每一项都恰到好处的抵消了!真不知道作者是怎么想出来这么巧妙地方法,各位可以看看证明过程自行体会。
1. 加速近似梯度方法
首先说我们要考虑的优化问题形式还是 \[ \text{minimize }\quad f(x)=g(x)+h(x) \] 其中 \(g\) 为光滑项,\(\text{dom }g=R^n\),\(h\) 为不光滑项,且为闭的凸函数,另外为了证明梯度方法的收敛性,跟前面类似,我们需要引入 Lipschitz-smooth 条件与强凸性质: \[ \frac{L}{2}x^Tx-g(x),\quad g(x)-\frac{m}{2}x^Tx \quad \text{convex} \] 其中 \(L>0,m\ge0\),\(m\) 可以等于 0,此时就相当于没有强凸性质。
然后我们就来看看 APG(Accelerated Proximal Gradient Methods) 方法到底是怎么下降的。首先取 \(x_0=v_0,\theta_0\in(0,1]\),对于每次迭代过程,包括以下几个步骤:
- 求 \(\theta_k\):\(\frac{\theta_{k}^{2}}{t_{k}}=\left(1-\theta_{k}\right) \gamma_{k}+m \theta_{k} \quad \text { where } \gamma_{k}=\frac{\theta_{k-1}^{2}}{t_{k-1}}\)
- 更新 \(x_k,v_k\):
\[ \begin{aligned} y &=x_{k}+\frac{\theta_{k} \gamma_{k}}{\gamma_{k}+m \theta_{k}}\left(v_{k}-x_{k}\right) \quad\left(y=x_{0} \text { if } k=0\right) \\ x_{k+1} &=\operatorname{prox}_{t_{k} h}\left(y-t_{k} \nabla g(y)\right) \quad(\bigstar)\\ v_{k+1} &=x_{k}+\frac{1}{\theta_{k}}\left(x_{k+1}-x_{k}\right) \end{aligned} \]
这里面的关键就是上面的 \((\bigstar)\) 式,对比前面讲过的近似梯度下降法实际上是 \[ x_{k+1} =\operatorname{prox}_{t_{k} h}\left(x_k-t_{k} \nabla g(x_k)\right) \] 所以这里实际上主要的变化就是将 \(x_k\) 换成了 \(y\),那么 \(y\) 跟 \(x_k\) 又有什么不同呢? \[ y=x_{k}+\frac{\theta_{k} \gamma_{k}}{\gamma_{k}+m \theta_{k}}\left(v_{k}-x_{k}\right)=x_{k}+\beta_{k}\left(x_{k}-x_{k-1}\right) \\ \beta_{k}=\frac{\theta_{k} \gamma_{k}}{\gamma_{k}+m \theta_{k}}\left(\frac{1}{\theta_{k-1}}-1\right)=\frac{t_{k} \theta_{k-1}\left(1-\theta_{k-1}\right)}{t_{k-1} \theta_{k}+t_{k} \theta_{k-1}^{2}} \] 可以看到 \(y=x_{k}+\beta_{k}\left(x_{k}-x_{k-1}\right)\) 实际上就是在 \(x_k\) 的基础上增加了一个“动量(Momentum)”,如下图所示
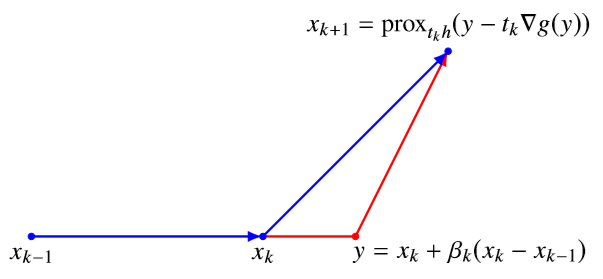
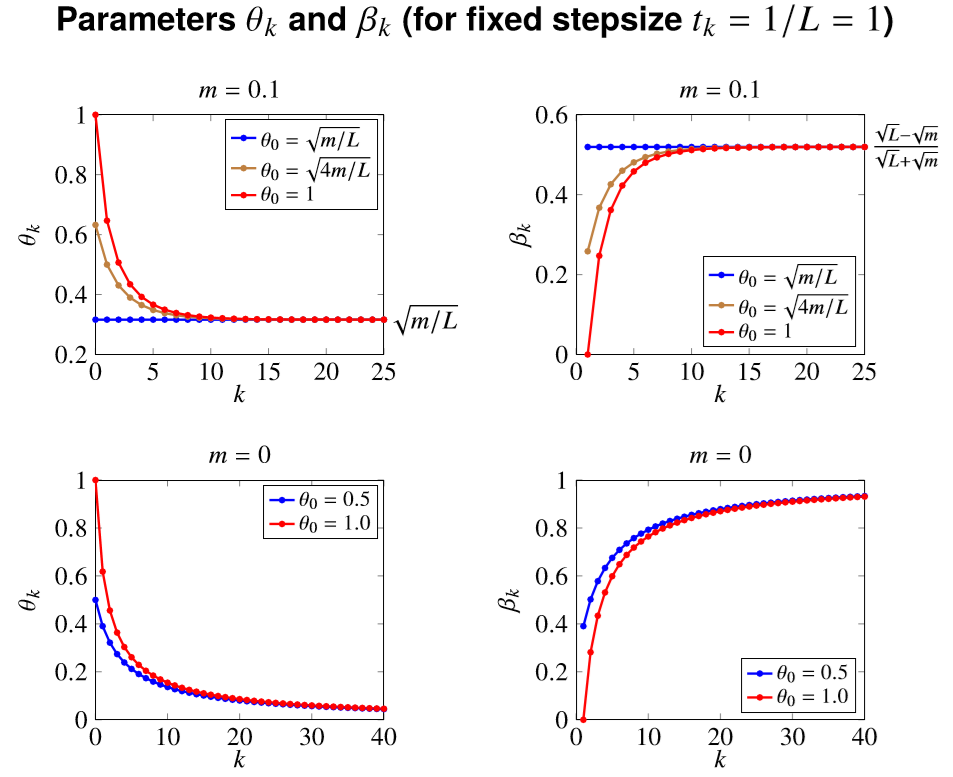
我们自然的要关注 \(\beta_k,\theta_k\) 的大小以及有什么性质。首先对于参数 \(\theta_k\) 它是根据二次方程一步步迭代出来的 \[ \frac{\theta_{k}^{2}}{t_{k}}=\left(1-\theta_{k}\right) \frac{\theta_{k-1}^{2}}{t_{k-1}}+m \theta_{k} \] 可以有几个主要结论:
- 如果 \(m>0\) 且 \(\theta_0=\sqrt{mt_0}\),那么有 \(\theta_k=\sqrt{mt_k},\forall k\)
- 如果 \(m>0\) 且 \(\theta_0\ge\sqrt{mt_0}\),那么有 \(\theta_k\ge\sqrt{mt_k},\forall k\)
- 如果 \(mt_k<,\),那么有 \(\theta_k<1\)
下面可以看几个关于 \(\theta_k,\beta_k\) 随着迭代次数 \(k\) 的变化:
如果我们取前面的 APG 方法中的 \(m=0\),然后消掉中间变量 \(v_k\),就可以得到 FISTA(Fast Iterative Shrinkage-Thresholding Algorithm) 算法 \[ \begin{aligned} y &=x_{k}+\theta_{k}\left(\frac{1}{\theta_{k-1}}-1\right)\left(x_{k}-x_{k-1}\right) \quad\left(y=x_{0} \text { if } k=0\right) \\ x_{k+1} &=\operatorname{prox}_{t_{k} h}\left(y-t_{k} \nabla g(y)\right) \end{aligned} \]
2. 收敛性分析
前面已经了解了基本原理,下面需要证明一下为什么他可以达到 \(O(1/k^2)\) 的收敛速度。作为类比,我们先回忆一下之前是怎么证明梯度方法/近似梯度方法的收敛性的? \[ \begin{aligned}(GD)\quad& f\left(x^{+}\right)-f^{\star} \leq \nabla f(x)^{T}\left(x-x^{\star}\right)-\frac{t}{2}\|\nabla f(x)\|_{2}^{2}\\\Longrightarrow &f\left(x^{+}\right)-f^{\star} \leq\frac{1}{2 t}\left(\left\|x-x^{\star}\right\|_{2}^{2}-\left\|x^{+}-x^{\star}\right\|_{2}^{2}\right) \\(SD)\quad& 2 t\left(f(x)-f^{\star}\right) \leq\left\|x-x^{\star}\right\|_{2}^{2}-\left\|x^{+}-x^{\star}\right\|_{2}^{2}+t^{2}\|g\|_{2}^{2} \\(PD)\quad& f\left(x^+\right) \leq f(z)+G_{t}(x)^{T}(x-z)-\frac{t}{2}\left\|G_{t}(x)\right\|_{2}^{2}-\frac{m}{2}\|x-z\|_{2}^{2}\\\Longrightarrow &f\left(x^{+}\right)-f^{\star} \leq \frac{1}{2 t}\left(\left\|x-x^{\star}\right\|_{2}^{2}-\left\|x^{+}-x^{\star}\right\|_{2}^{2}\right)\end{aligned} \] 对于这一节的 APG 方法,证明思路是首先证明下面的迭代式子成立 \[ f\left(x_{i+1}\right)-f^{\star}+\frac{\gamma_{i+1}}{2}\left\|v_{i+1}-x^{\star}\right\|_{2}^{2} \\\quad \leq \left(1-\theta_{i}\right)\left(f\left(x_{i}\right)-f^{\star}+\frac{\gamma_{i}}{2}\left\|v_{i}-x^{\star}\right\|_{2}^{2}\right) \quad \text { if } i\ge1 \] 对比后发现实际上之前我们考虑的是 \(f(x^+)-f^\star\) 的迭代式子,而这里我们加了一个小尾巴,考虑 \(f(x^+)-f^\star + \frac{\gamma_{i+1}}{2}\left\|v_{i+1}-x^{\star}\right\|_{2}^{2}\) 的收敛速度。证明一会再说,有了这个迭代关系式,那么就可以有 \[ \begin{aligned}f\left(x_{k}\right)-f^{\star} & \leq \lambda_{k}\left(\left(1-\theta_{0}\right)\left(f\left(x_{0}\right)-f^{\star}\right)+\frac{\gamma_{1}-m \theta_{0}}{2}\left\|x_{0}-x^{\star}\right\|_{2}^{2}\right) \\& \leq \lambda_{k}\left(\left(1-\theta_{0}\right)\left(f\left(x_{0}\right)-f^{\star}\right)+\frac{\theta_{0}^{2}}{2 t_{0}}\left\|x_{0}-x^{\star}\right\|_{2}^{2}\right)\end{aligned} \] 其中 \(\lambda_1=1\),\(\lambda_{k}=\prod_{i=1}^{k-1}\left(1-\theta_{i}\right) \text { for } k>1\),如果能证明 \(\lambda_k\sim O(1/k^2)\) 就能证明收敛速度了。好了,下面就是非常巧妙而又繁琐的证明过程了。
这个证明过程很繁琐,为了更容易顺下来,这里列出来其中几个关键的等式/不等式(为了简便省略了下标):
- \(\gamma^+-m\theta=(1-\theta)\gamma\)(易证)
- \(\gamma^+v^+=\gamma ^+ v+ m\theta(y-v)-\theta G_t(y)\)
- \(\begin{aligned} f\left(x^{+}\right)-f^{\star} \leq &(1-\theta)\left(f(x)-f^{\star}\right)-G_{t}(y)^{T}\left((1-\theta) x+\theta x^{\star}-y\right) -\frac{t}{2}\left\|G_{t}(y)\right\|_{2}^{2}-\frac{m \theta}{2}\left\|x^{\star}-y\right\|_{2}^{2} \end{aligned}\)
- \(\begin{aligned} \frac{\gamma^{+}}{2}\left\|v^{+}-x^{\star}\right\|_{2}^{2} \leq & \frac{\gamma^{+}-m \theta}{2}\left\|v-x^{\star}\right\|_{2}^{2}+G_{t}(y)^{T}\left(\theta x^{\star}+(1-\theta) x-y\right) +\frac{t}{2}\left\|G_{t}(y)\right\|_{2}^{2}+\frac{m \theta}{2}\left\|x^{\star}-y\right\|_{2}^{2} \end{aligned}\)
(3,4) 条结合就能得到上面的迭代关系式,很多项刚好消掉。下面就是要证明 \(\lambda_k\sim O(1/k^2)\): \[ \gamma_{k+1}=(1-\theta_k)\gamma_k+m\theta_k \\\lambda_{i+1}=\left(1-\theta_{i}\right) \lambda_{i}=\frac{\gamma_{i+1}-\theta_{i} m}{\gamma_{i}} \lambda_{i} \leq \frac{\gamma_{i+1}}{\gamma_{i}} \lambda_{i} \Longrightarrow \lambda_k\le \gamma_k/\gamma_1 \\\frac{1}{\sqrt{\lambda_{i+1}}}- \frac{1}{\sqrt{\lambda_{i}}} \ge \frac{\theta_i}{2\sqrt{\lambda_{i+1}}}=\frac{1}{2}\sqrt{\gamma_1t_i} \] 然后就可以有 \[ \lambda_{k} \leq \frac{4}{\left(2+\sqrt{\gamma_{1}} \sum_{i=1}^{k-1} \sqrt{t_{i}}\right)^{2}}=\frac{4 t_{0}}{\left(2 \sqrt{t_{0}}+\theta_{0} \sum_{i=1}^{k-1} \sqrt{t_{i}}\right)^{2}} \] 如果取 \(t_0=t_k=1/L,\theta_0=1\),则有 \[ \lambda_k\le \frac{4}{(k+1)^2} \] 如果有强凸性质,也即 \(m>0\),那么取 \(\theta_0\ge\sqrt{mt_0}\Longrightarrow \theta_k\ge \sqrt{mt_k}\) \[ \lambda_k \le \Pi_{i=1}^{k-1}(1-\sqrt{mt_i}) \] 这就可以变成线性收敛了。