模糊数学笔记 7:层次分析法
日常生活中有许多决策问题。决策是指在面临多种方案时需要依据一定的标准选择某一种方案。 比如买钢笔,一般要依据质量、颜色、实用性、价格、外形等方面的因素选择某一支钢笔。 又比如假期旅游,是去风光秀丽的苏州,还是去迷人的北戴河,或者是去山水甲天下的桂林,一般会依据景色、费用、食宿条件、旅途等因素选择去哪个地方。
我们可以利用上一节讲的模糊综合评判的方法,对每一个备选方案都进行一次打分,最后取分最高的。不过既然这是新的一篇笔记,肯定还有其他方法啦。美国运筹学家托马斯.赛迪(T. Saaty等人)20世纪在七十年代为美国国防部提出了一种能有效处理这类问题的实用方法——层次分析法。
1. 层次分析法 AHP
层次分析法(Analytic Hierarchy Process, AHP)是一种定性和定量相结合的、系统化的、层次化的分析方法。是系统分析问题的数学工具之一。层次分析法一般包含以下几个主要步骤:
- 建立层次结构模型
- 构造成对比较矩阵
- 层次单排序及一致性检验
- 层次总排序及其一致性检验
下面逐步解释各个步骤。
1.1 建立层次结构模型
一般分为三层,最上面为目标层,最下面为方案层,中间是准则层或指标层。
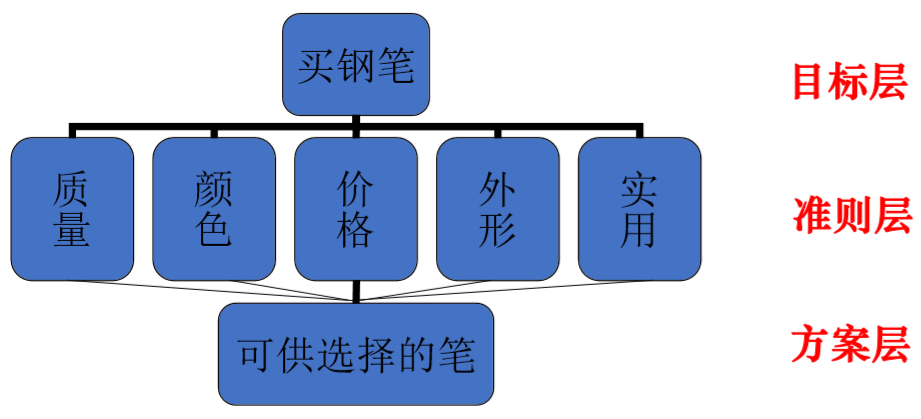
若上层的每个因素都支配着下一层的所有因素,或被下一层所有因素影响,称为完全层次结构,否则称为不完全层次结构(都是概念性的东西,我觉得不重要,只要理解层次结构就好啦)。
1.2 构造成对比较矩阵
设某层有 \(n\) 个因素,\(X=\{x_1,...,x_n\}\) 。要比较它们对上一层某一准则(或目标)的影响程度,也就是把 \(n\) 个因素对上 层某一目标的影响程度排序。这种比较是凉凉元素之间的比较,比较时取1~9 尺度。用 \(a_{ij}\) 表示第 \(i\) 个因素相对于第 \(j\) 个因素的比较结果,则有 \(a_{ij}=1/a_{ji}\)(这里应该完全是人为定义) \[ A=\left(a_{i j}\right)_{n \times n}=\left(\begin{array}{llll}a_{11} & a_{12} & \cdots & a_{1 n} \\a_{21} & a_{22} & \cdots & a_{2 n} \\\cdots & \cdots & \cdots & \cdots \\a_{n 1} & a_{n 2} & \cdots & a_{n n}\end{array}\right) \] \(A\) 则称为成对比较矩阵。
这里的成对比较矩阵有点像图论里的邻接矩阵,就是说任意两个元素都要进行一次比较。
前边说了比较尺度我们一般选择 1~9,并且一般选择奇数(不知道为啥),各尺度含义为
| 尺度 | 含义 |
|---|---|
| 1 | 第 \(i\) 个因素与第 \(j\) 个因素的影响相同 |
| 3 | 第 \(i\) 个因素比第 \(j\) 个因素的影响稍强 |
| 5 | 第 \(i\) 个因素比第 \(j\) 个因素的影响强 |
| 7 | 第 \(i\) 个因素比第 \(j\) 个因素的影响明显强 |
| 9 | 第 \(i\) 个因素比第 \(j\) 个因素的影响绝对地强 |
2,4,6,8 表示第 \(i\) 个因素相对于第 \(j\) 个因素的影响介于上述两个相邻等级之间。
根据上面的定义,可以知道成对比较矩阵 \(A\) 满足以下三条性质:
- \(a_{ij}>0\)
- \(a_{ij}=1/a_{ji}\)
- \(a_{ii}=1\)
此时 \(A\) 也成为正互反阵。
比如旅游问题中,第二层 \(A\) 的各因素对目标层 \(Z\) 的影响两两比较结果如下:
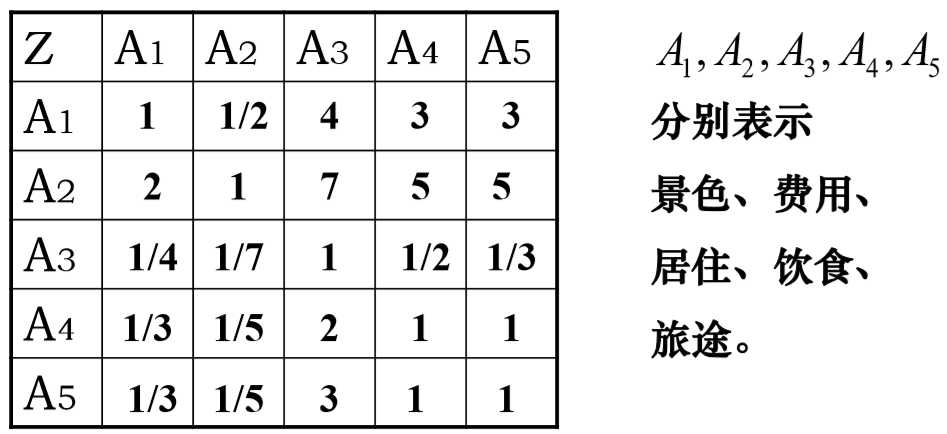
Remarks:(我个人觉得)一般认为各因素是有序的,也就是说如果 \(x_1>x_2,x_2>x_3\),那么应该有 \(x_1>x_3\),这样一来互反矩阵 \(A\) 就需要满足一定的性质了。
1.3 层次单排序及一致性检验
层次单排序就是确定下层各因素对上层某因素影响程度的过程。 用权值表示影响程度,先从一个简单的例子看如何确定权值。 例如 一块石头重量记为 1,打碎分成 n 个小块,各块的重量分别记为 \(w_1,...,w_n\),那么可以得到成对比较矩阵 \[ A=\left(a_{i j}\right)_{n \times n}=\left(\begin{array}{llll}1 & \frac{w_1}{w_2} & \cdots & \frac{w_1}{w_n} \\\frac{w_2}{w_1} & 1 & \cdots & \frac{w_2}{w_n} \\\cdots & \cdots & \cdots & \cdots \\\frac{w_n}{w_1} & \frac{w_n}{w_2} & \cdots & 1\end{array}\right) \] 根据上面的定义可以有 \(a_{ik}a_{kj}=a_{ij},\forall i,j\)。前面我们提到的互反矩阵并不满足这个性质,如果互反矩阵 \(A\) 满足此性质,则我们称其为一致阵。一致阵有以下性质:
- \(a_{ij}=1/a_{ji},a_{ii}=1\)
- \(a_{ik}a_{kj}=a_{ij}\)
- \(A^T\) 也是一致阵
- \(A\) 的各行成比例,故 \(rank(A)=1\)
- \(A\) 的最大特征值为 \(n\),其余特征值均为 0
- \(A\) 的任一列都是对应于特征根的特征向量。
若成对比较矩阵是一致阵,则我们自然会取对应于最大特征根 \(n\) 的归一化特征向量 \(\{w_1,...,w_n\}\),且 \(\sum w_i=1\),\(w_i\) 即表示下层第 \(i\) 个因素对上层某因素影响程度的权值。若成对比较矩阵不是一致阵,Saaty等人建议用其最大特征根对应的归一化特征向量作为权向量 \(\boldsymbol{w}\),这样确定权向量的方法称为特征根法。
定理: \(n\) 阶互反阵 \(A\) 的最大特征根 \(\lambda\ge n\),当且仅当 \(\lambda=n\) 时,\(A\) 为一致阵。
由于 \(\lambda\) 连续的依赖于 \(a_{ij}\),则 \(\lambda\) 比 \(n\) 大的越多,\(A\) 的不一致性越严重。用最大特征值对应的特征向量作为被比较 因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。因而可以用 \(\lambda-n\) 数值的大小来衡量 \(A\) 的不一致程度。
一致性指标:\(CI=\frac{\lambda-n}{n-1}\)
随即一致性指标:构造 500 个成对比较矩阵 \(A_1,...,A_{500}\),可得一致性指标 \(CI_1,...,CI_{500}\) \[ R I=\frac{C I_{1}+C I_{2}+\cdots C I_{500}}{500}=\frac{\frac{\lambda_{1}+\lambda_{2}+\cdots+\lambda_{500}}{500}-n}{n-1} \] 对于 1 阶和 2 阶成对比较矩阵,总是有 \(RI=0\)。一般有以下表格,使用时直接查表
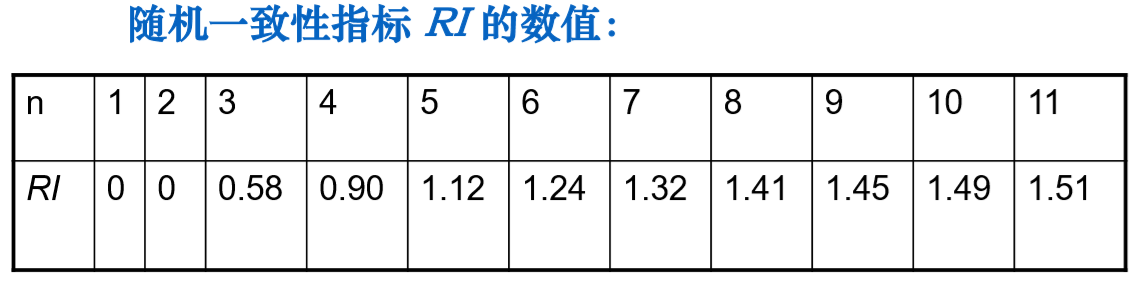
有一些文献取随机取 1000 个成对矩阵,分别计算它们的一致性指标 CI 进而得到如下的随机一致性指标 RI:

一般,当一致性比率 \(CR=CI/RI<0.1\) 时,认为 \(A\) 的不一致程度在容许范围之内,可用其最大特征值对应的归一化特征向量作为权向量,否则要重新构造成对比较矩阵,对 \(A\) 加以调整。
一致性检验:上面利用一致性指标及随机一致性指标的数值表,进而计算一致性比率并进行判断的过程称为是对 \(A\) 的一致性检验。
1.4 层次总排序及其一致性检验
确定某层所有因素对于总目标相对重要性的排序权值过程, 称为层次总排序。
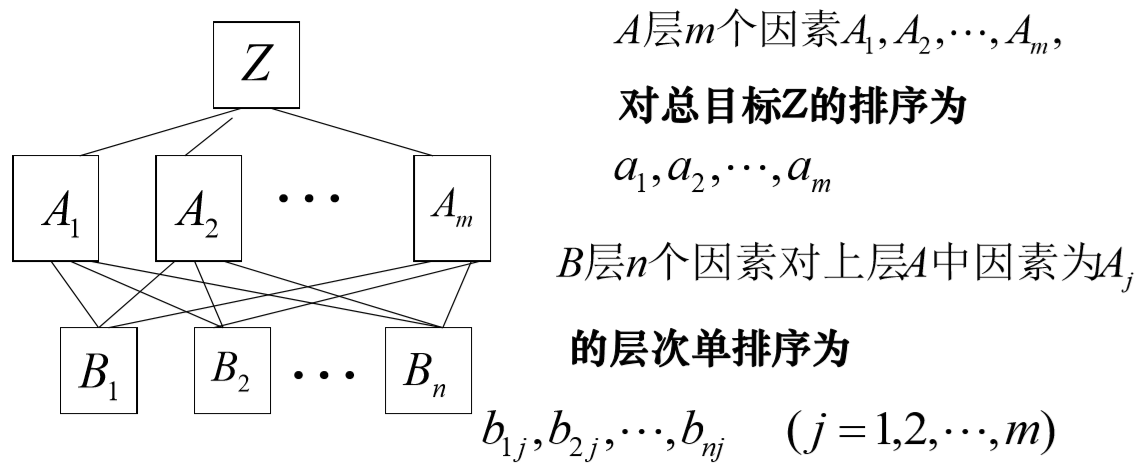
那么 \(B\) 层第 \(i\) 个因素对总目标的权值为 \(B_i = \sum_j a_jb_{ij}\)。
假设 \(B\) 层 \(B_1,...,B_n\) 对上层 \(A\) 中因素 \(A_j\) 的层次单排序一致性指标为 \(CI_j\),随机一致性指标为 \(RI_j\),则层次总排序的一致性比率为: \[ CR=\frac{a_1CI_1+\cdots+a_mCI_m}{a_1RI_1+\cdots+a_mRI_m} \] 当 \(CR<0.1\) 时,认为层次总排序通过一致性检验。到此,根据最下层(决策层)的层次总排序做出最后决策。